MYSQL 索引(一)
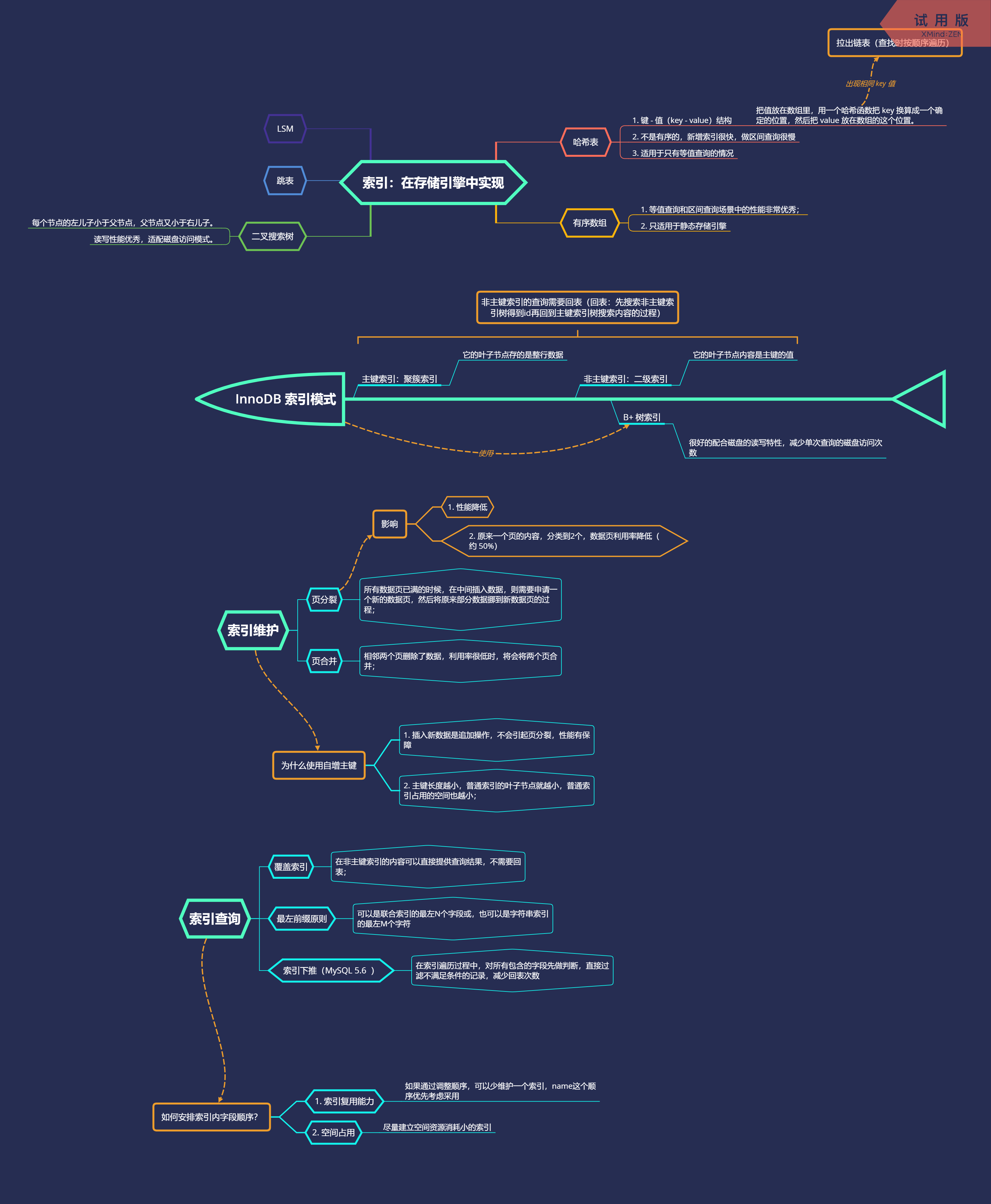
索引:在存储引擎实现
哈希表
1. 键 - 值(key - value)结构
- 把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。
2. 不是有序的,新增索引很快,做区间查询很慢
3. 适用于只有等值查询的情况
有序数组
- 等值查询和区间查询场景中的性能非常优秀;
- 只适用于静态存储引擎
二叉搜索树
- 每个节点的左儿子小于父节点,父节点又小于右儿子。
- 读写性能优秀,适配磁盘访问模式。
跳表
LSM
拉出链表(查找时按顺序遍历)
InnoDB 索引模式
主键索引:聚簇索引
- 它的叶子节点存的是整行数据
非主键索引:二级索引
- 它的叶子节点内容是主键的值
B+ 树索引
- 很好的配合磁盘的读写特性,减少单次查询的磁盘访问次数
概要: 非主键索引的查询需要回表(回表:先搜索非主键索引树得到id再回到主键索引树搜索内容的过程)
索引维护
页分裂
- 所有数据页已满的时候,在中间插入数据,则需要申请一个新的数据页,然后将原来部分数据挪到新数据页的过程;
页合并
- 相邻两个页删除了数据,利用率很低时,将会将两个页合并;
影响
- 性能降低
- 原来一个页的内容,分类到2个,数据页利用率降低(约 50%)
为什么使用自增主键
- 插入新数据是追加操作,不会引起页分裂,性能有保障
- 主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也越小;
索引查询
覆盖索引
- 在非主键索引的内容可以直接提供查询结果,不需要回表;
最左前缀原则
- 可以是联合索引的最左N个字段或,也可以是字符串索引的最左M个字符
索引下推(MySQL 5.6 )
- 在索引遍历过程中,对所有包含的字段先做判断,直接过滤不满足条件的记录,减少回表次数
如何安排索引内字段顺序?
1. 索引复用能力
- 如果通过调整顺序,可以少维护一个索引,name这个顺序优先考虑采用
2. 空间占用
- 尽量建立空间资源消耗小的索引
Xmind 思维导图
本文为Larwas原创文章,转载无需和我联系,但请注明来自larwas博客 https://larwas.com
- 上一篇: windows 中 phpstrome 配置运行 PHP 项目
- 下一篇: mysql 全局锁和表锁

请先登录后发表评论
- latest comments
- 总共0条评论
最新评论