3步控制AI生成图像为你所用,全网最详细Controlnet教程来了
AI生成图像带来最大的问题就是不可控,随机性过大造成很难真正的产生出可被日常工作环境应用的图像。今天我带来SD的Controlnet教程,让AI生成的100%可控,大大提高文生图的应用场景。
Controlnet教程:前期准备工作
1、科学上网工具
2、Stable Diffusion(没安装的看下之前的攻略)
Controlnet教程:插件安装
###第一步:启动Stable Diffusion
点击进入Extension tab,选 从网上安装(Install from URL),在URL栏(扩展的git仓库网址)里面粘贴 https://github.com/Mikubill/sd-webui-controlnet 这个网址。
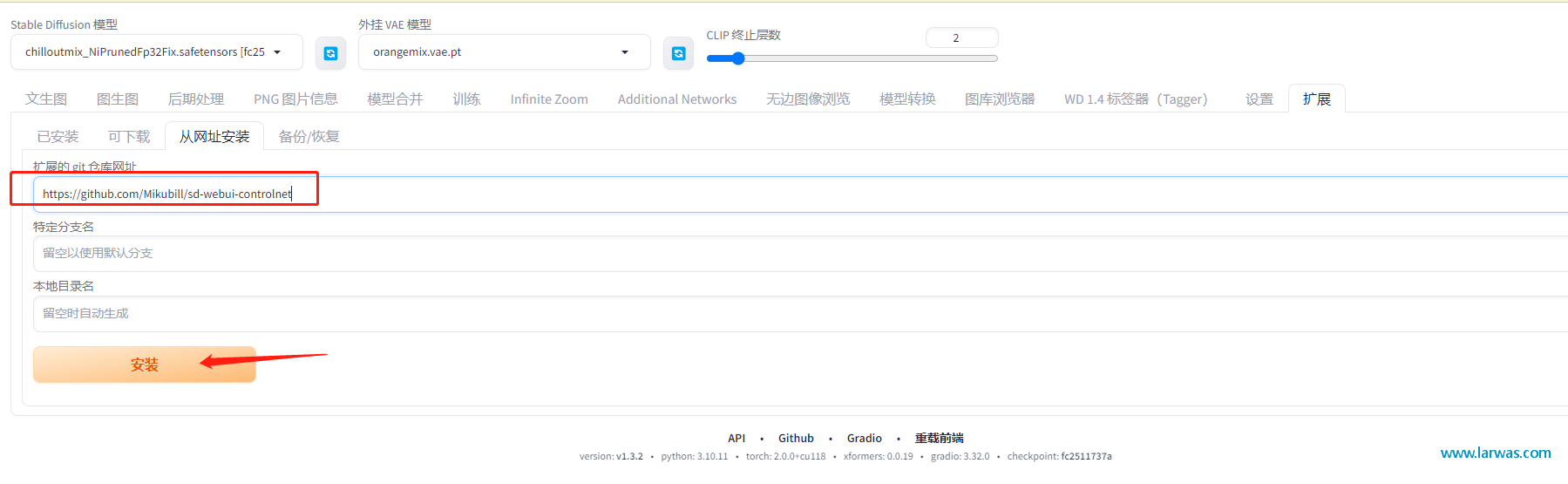 因为国内网络原因,会有下载失败的可能性,多换几个线路试几次就会安装成功。
因为国内网络原因,会有下载失败的可能性,多换几个线路试几次就会安装成功。
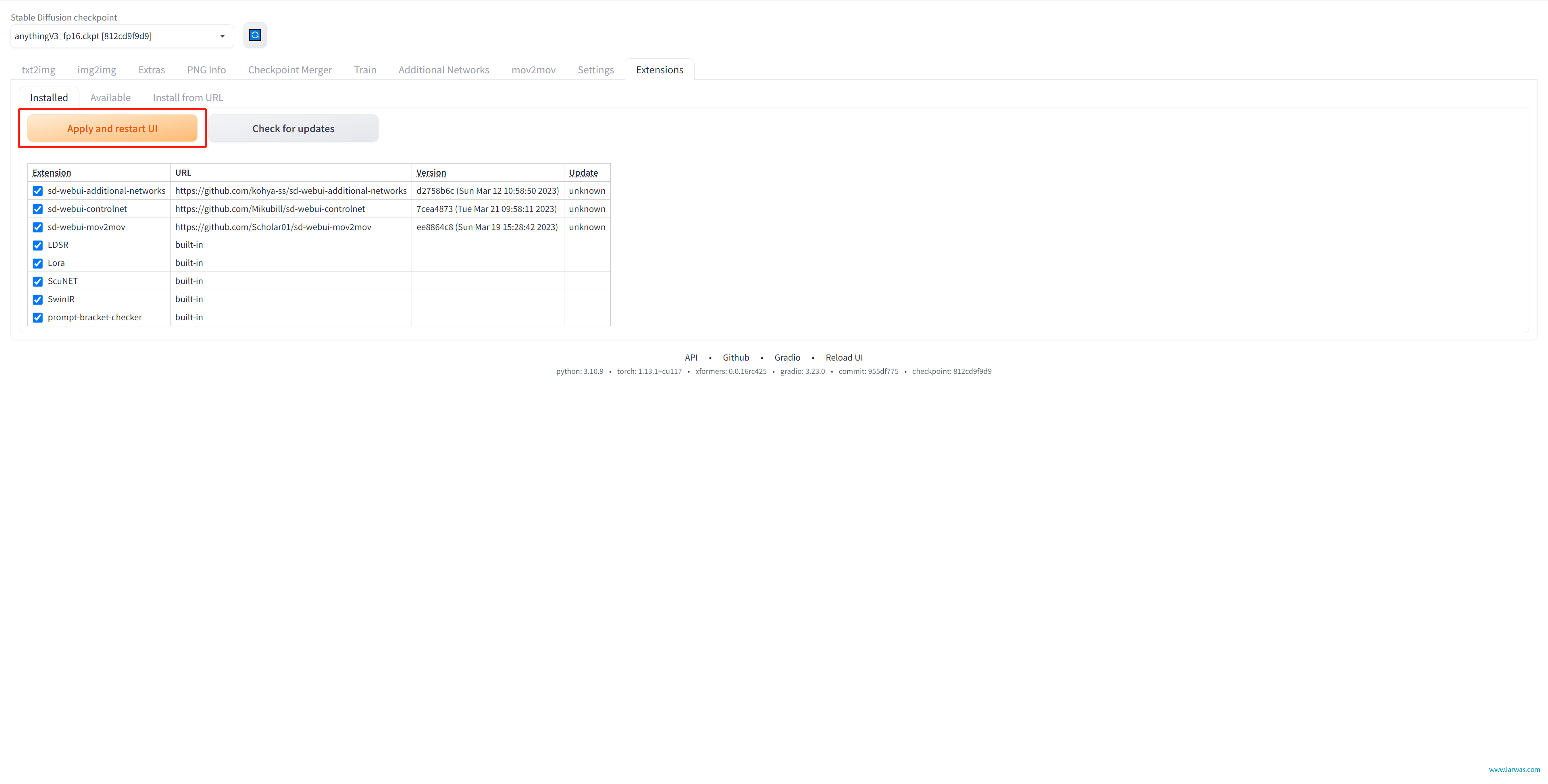
第二步:在Extension tab下面,进入Installed界面,点击Apply and restart UI就可以启用Controlnet了。
第三步:点击链接
(https://huggingface.co/lllyasviel/ControlNet/tree/main/models)进入,下载 controlnet 的 model 至SD文件夹:extensions:sd-webui-controlnet:models 文件夹。
Controlnet的model比较多,而且每种model都有它对应的使用场景,对于硬盘空间比较小的同学来说非常不友好。这里我推荐几个比较常用的:canny、depth、hed、openpose。
Controlnet教程:使用指南
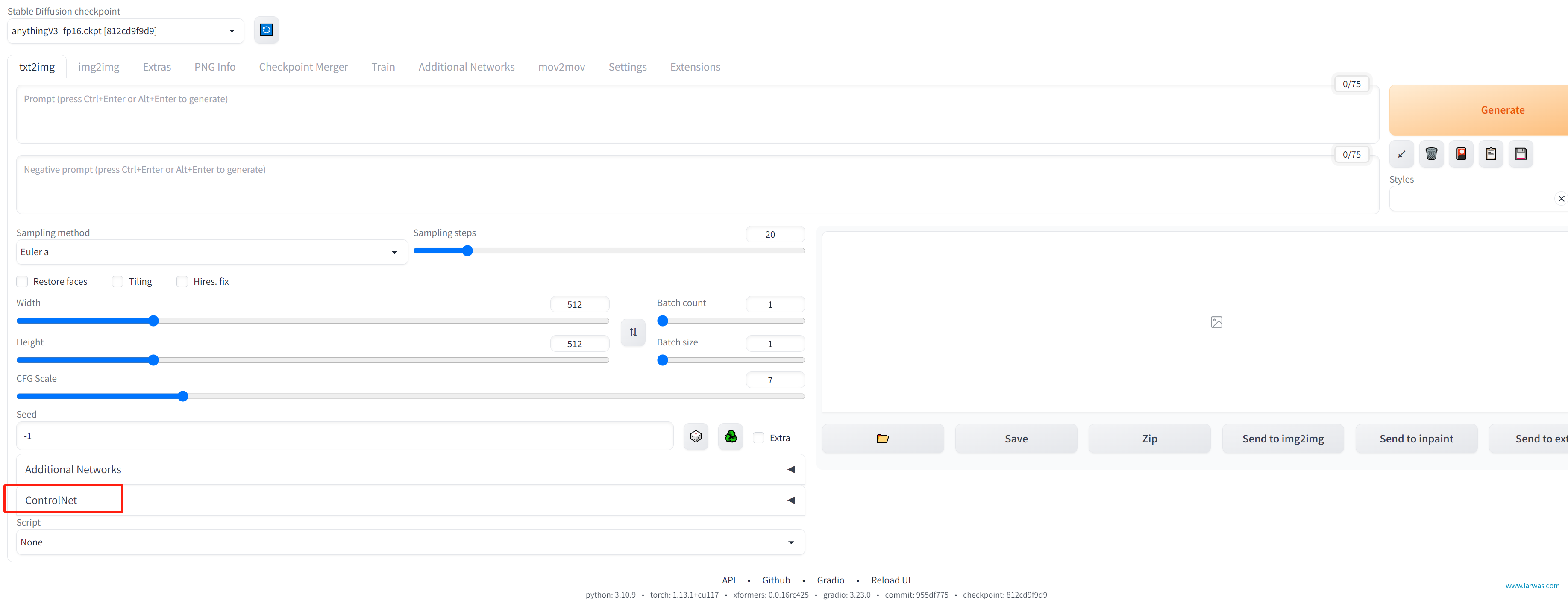
1、无论是txt2img还是img2img,你的SD界面左下方应该有Controlnet的选项了,点击打开它。
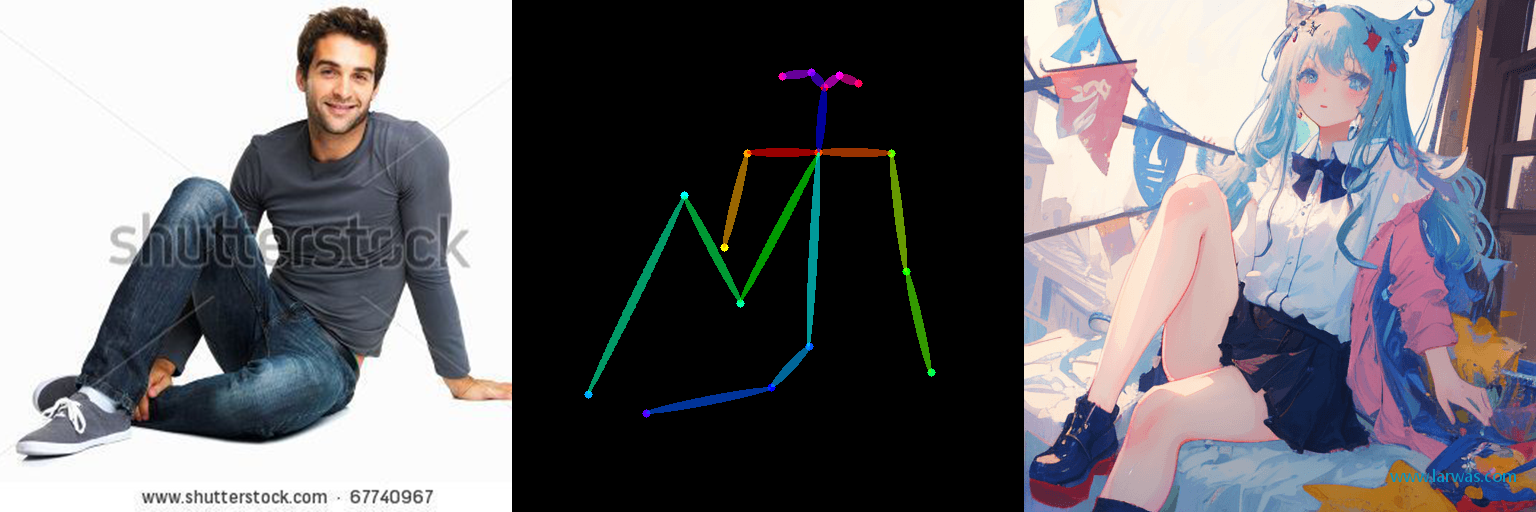
2、选择Enable,把你要生成图像需要模仿的参考动作图拖入框内,点击下方Preview annotator result就可以看到controlnet识别的动作效果了。
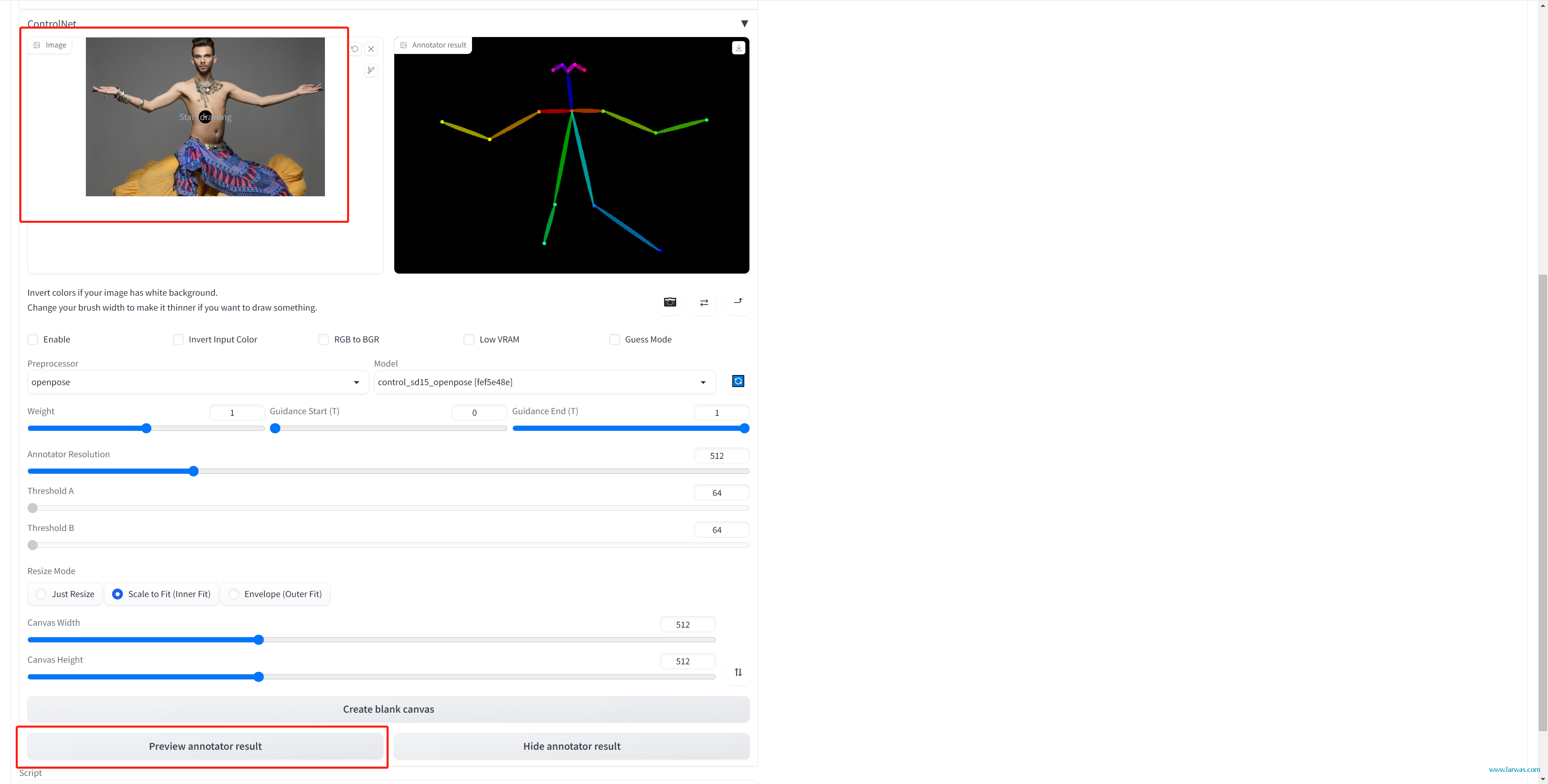 3、下面说一下常规设置的参数
(1)Preprocessor和model要选一样的,不然会报错。
3、下面说一下常规设置的参数
(1)Preprocessor和model要选一样的,不然会报错。
(2)Weight:通常不要超过1,其实平时放到0.2~0.3左右就基本可以控制动作了,权重加大之后会让穿着、背景等等更多的细节被强行控制。
(3)尺寸:Canvas Width和Canvas Height要和你上面文生图要生的width和height保持一致,这点需要注意!
(4)Annotator Resolution:预设512够用,但是你调的越大,他对动作和细节的识别越清晰相对你显卡的压力就越大,所以根据实际情况来决定,比如你希望生成的动作他识别不出来,可以通过拉高这个数值来提高识别概率。
4、说一下几个Preprocessor (1)Canny:精描识别对象细节,对于主体与背景色系相同的图像不好使
(2)depth:识别不同景深下的物体,适合不同层次下的应用
(3)hed:粗描识别对象轮廓,对于细节的处理不到位
(4)openpose:识别动作并生成动作骨骼图,适合动作幅度大精度要求高的场景
(5)mlsd、normal、scribble、seg我不常用,就不过多评价。我看到有一些进阶的大佬会使用seg进行分步骤处理图像,对于同一个图像使用不同controlnet分别控制生成结果,这个就比较深入了,未来有机会再讲。
5、最后给几个官方案例供参考


本文为Larwas原创文章,转载无需和我联系,但请注明来自larwas博客 https://larwas.com
- 上一篇: epic 无法下载
- 下一篇: 2023年最新版安装使用LoRA教程,训练独属于你的AI模型

- latest comments
- 总共0条评论
最新评论