2023年最新版安装使用LoRA教程,训练独属于你的AI模型
经过这几个月AIGC的高速发展,单纯使用AI绘图工具已经不能满足你的创作需求了。新出现的许多神模型例如RealisticVision、Chilloutmix在真人成像层面带来了令人震惊和满意的效果。下面我将来带领大家使用LoRA训练出独属于你的AI模型,为创作带来更多的灵感!
使用LoRA教程训练AI模型:必备预装工具
1、科学上网工具
2、Stable Diffusion Automatic1111,如果没安装这个要先看一下我前面的教程 (点这里打开教程)
3、Python3.10
4、Git
5、Microsoft Visual Studio
使用LoRA教程训练AI模型:安装教程
第一步:进入kohya_ss链接,下拉至Installation部分(https://github.com/bmaltais/kohya_ss)
 第二步:使用管理员模式运行Windows PowerShell
第二步:使用管理员模式运行Windows PowerShell
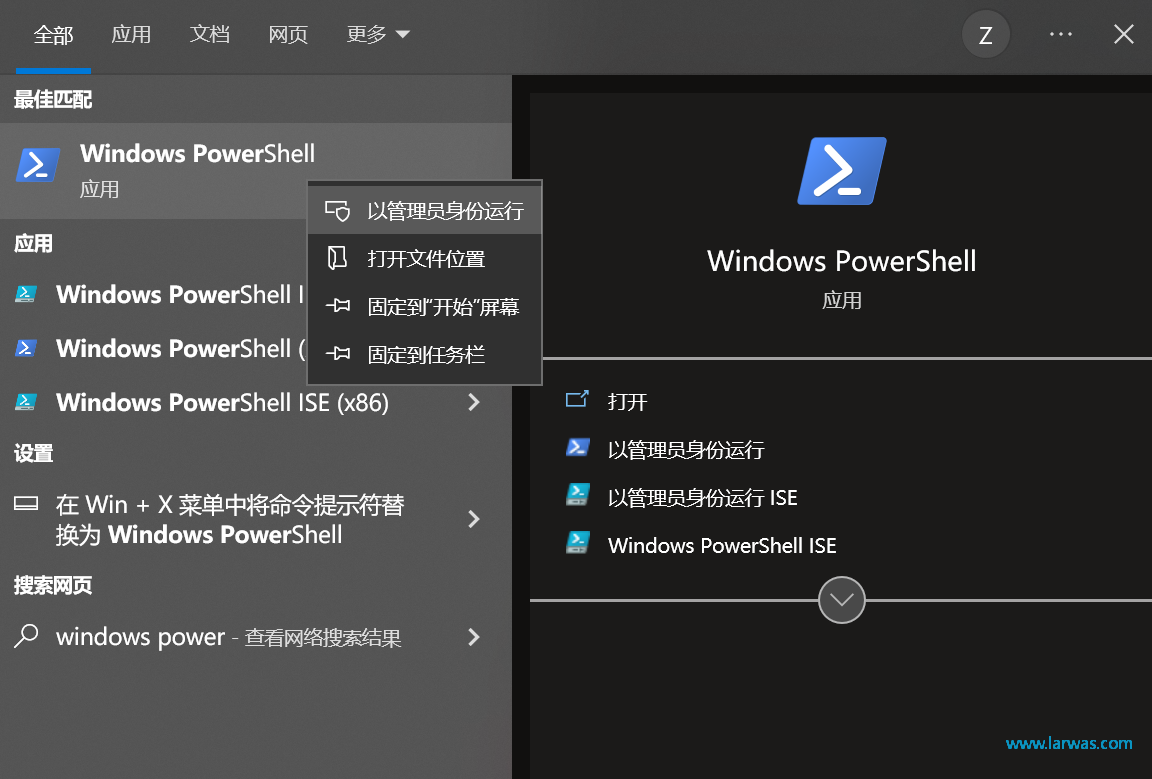 第三步:跟随Installation教程,输入指令
Set-ExecutionPolicy Unrestricted,提示框回答“a”
第三步:跟随Installation教程,输入指令
Set-ExecutionPolicy Unrestricted,提示框回答“a”
 第四步:关闭Powershell,在C盘document中新建文件夹“Kohya”
在新建文件夹路径中输入“Powershell”再次打开操作台
第四步:关闭Powershell,在C盘document中新建文件夹“Kohya”
在新建文件夹路径中输入“Powershell”再次打开操作台
 第五步:回到github网页,复制页面中的代码到Powershell中运行
第五步:回到github网页,复制页面中的代码到Powershell中运行
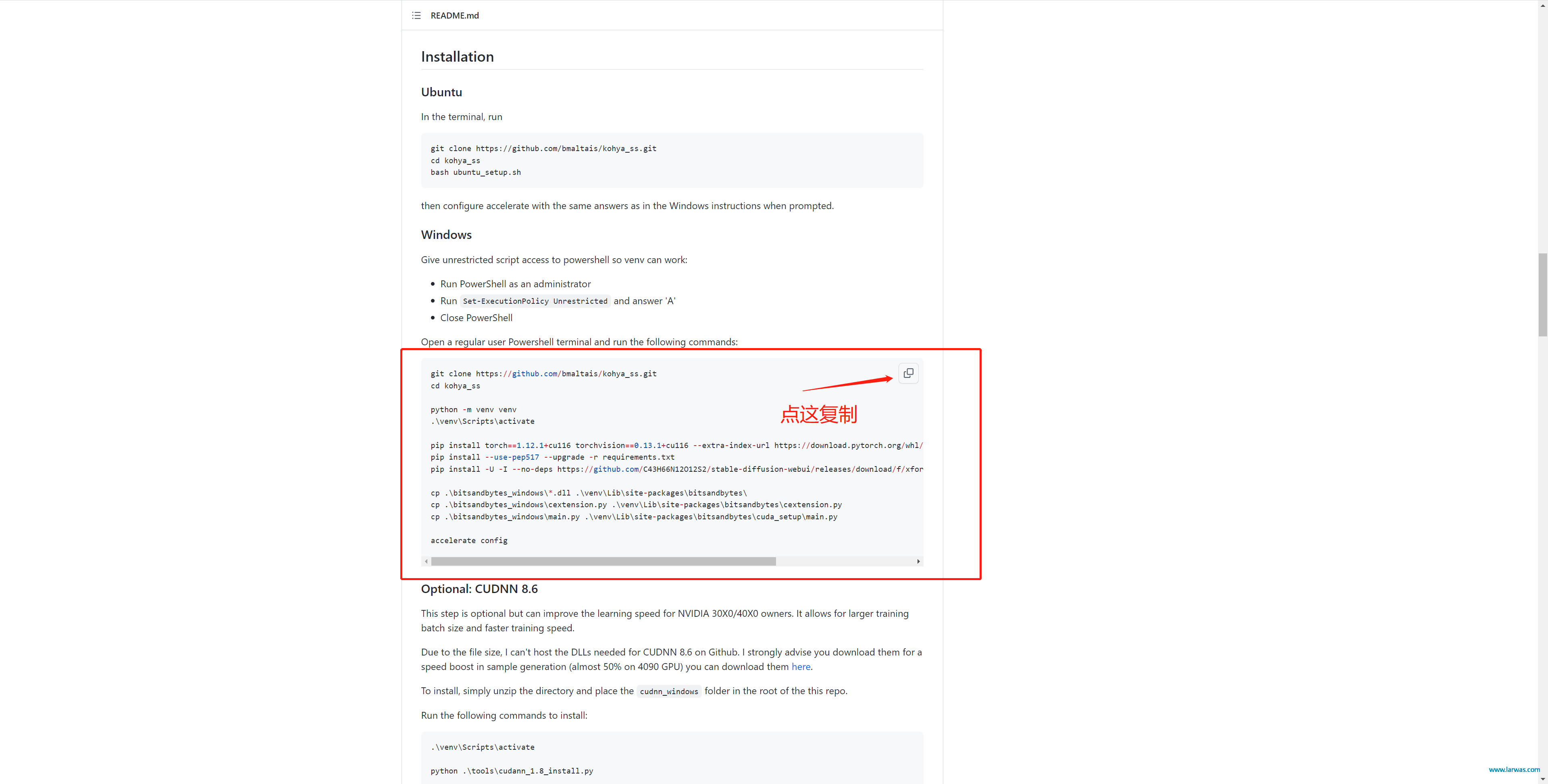 第六步:网站会持续安装一阵,然后系统会问你一些问题,按照我截图示意的回答即可
第六步:网站会持续安装一阵,然后系统会问你一些问题,按照我截图示意的回答即可
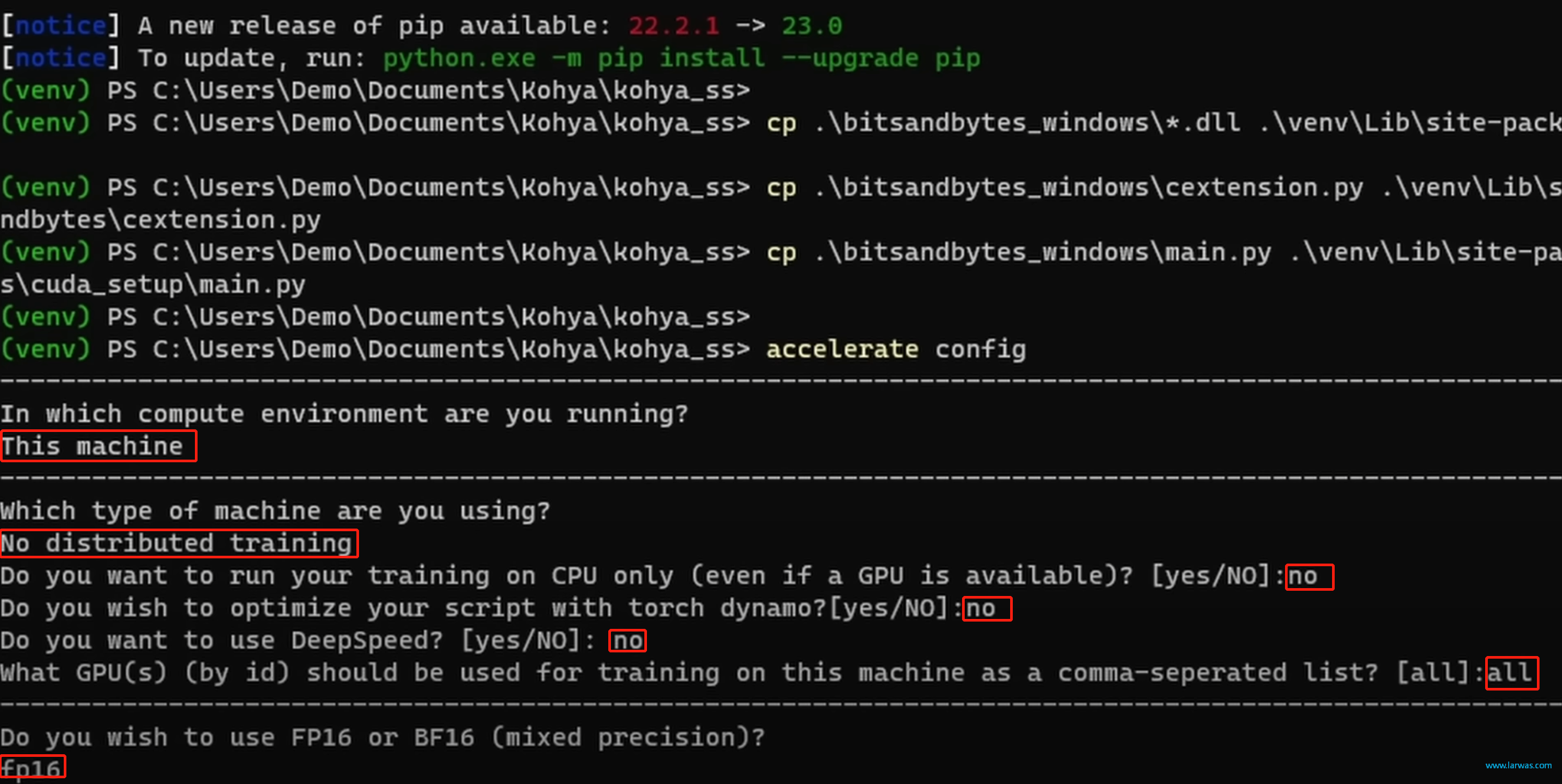 第七步:N卡3和4开头以上的用户,回到网页下载CUDNN,然后将文件解压到KohyaSS文件夹中(在你前面创建的新文件夹里面)
第七步:N卡3和4开头以上的用户,回到网页下载CUDNN,然后将文件解压到KohyaSS文件夹中(在你前面创建的新文件夹里面)
 LoRA生成AI模型:下载cudnn
LoRA生成AI模型:下载cudnn
 LoRA生成AI模型:kohyass文件夹
第八步:继续回到Github,复制这段代码然后在Powershell中运行
LoRA生成AI模型:kohyass文件夹
第八步:继续回到Github,复制这段代码然后在Powershell中运行
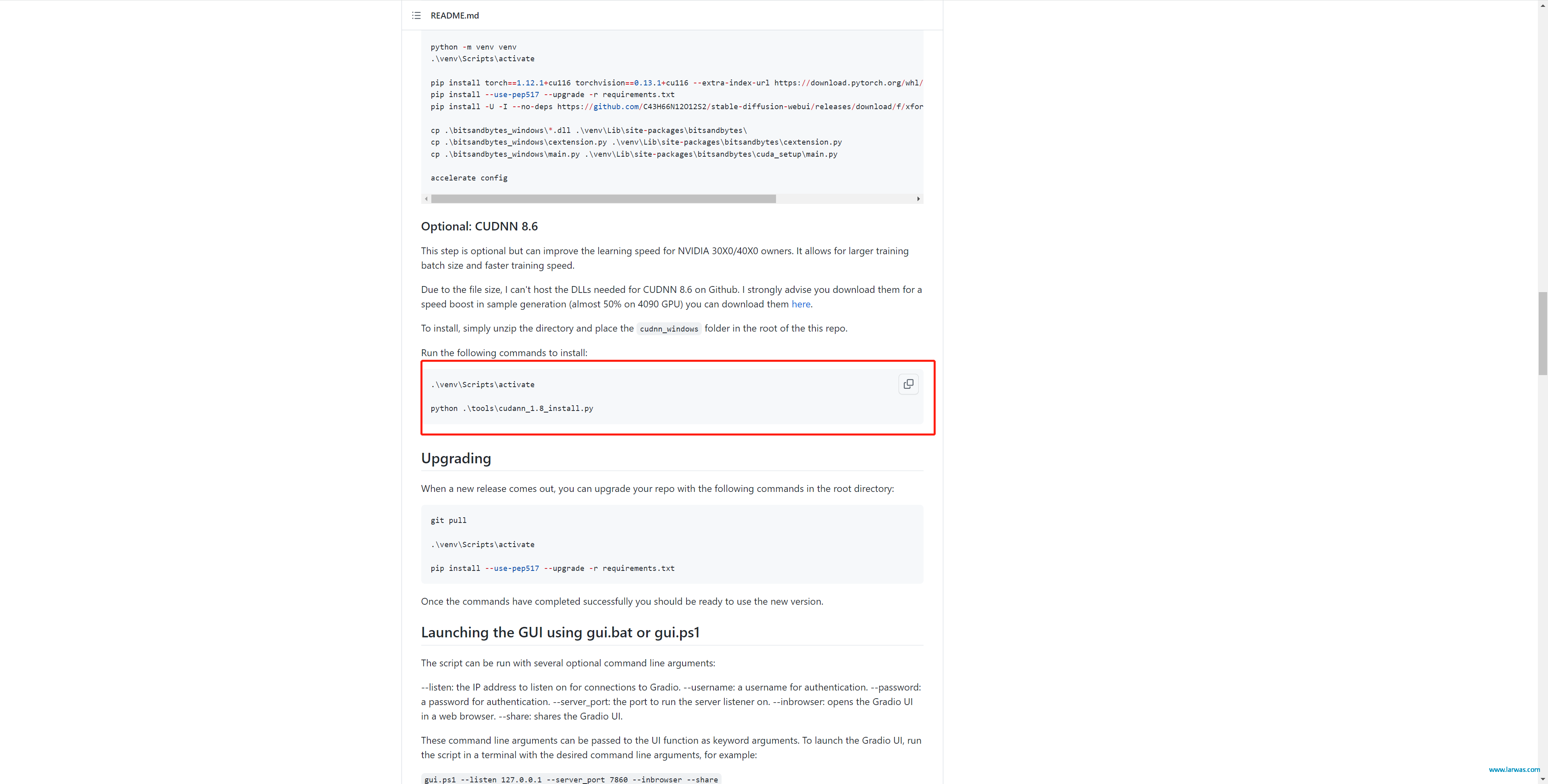 LoRA生成AI模型:安装cudnn
第九步:进入Kohyass文件夹,找到upgrade.ps1文件夹,右键点击选择Run with Powershell
LoRA生成AI模型:安装cudnn
第九步:进入Kohyass文件夹,找到upgrade.ps1文件夹,右键点击选择Run with Powershell
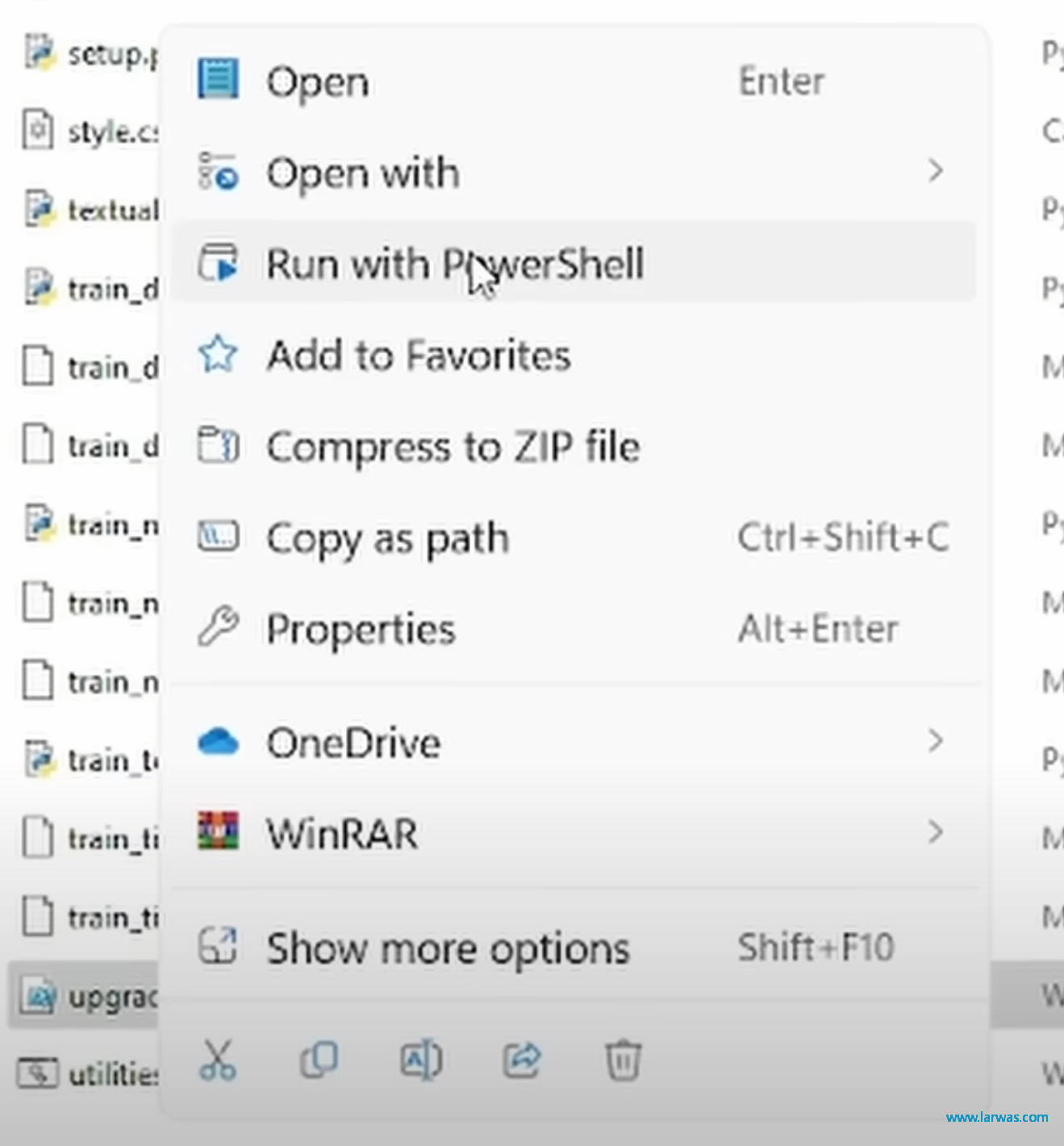 LoRA生成AI模型:LoRA更新
第十步:至此我们完成了Lora的安装,双击gui.bat运行,然后将控制台给的域名复制到浏览器内就可以开始使用啦!
LoRA生成AI模型:LoRA更新
第十步:至此我们完成了Lora的安装,双击gui.bat运行,然后将控制台给的域名复制到浏览器内就可以开始使用啦!
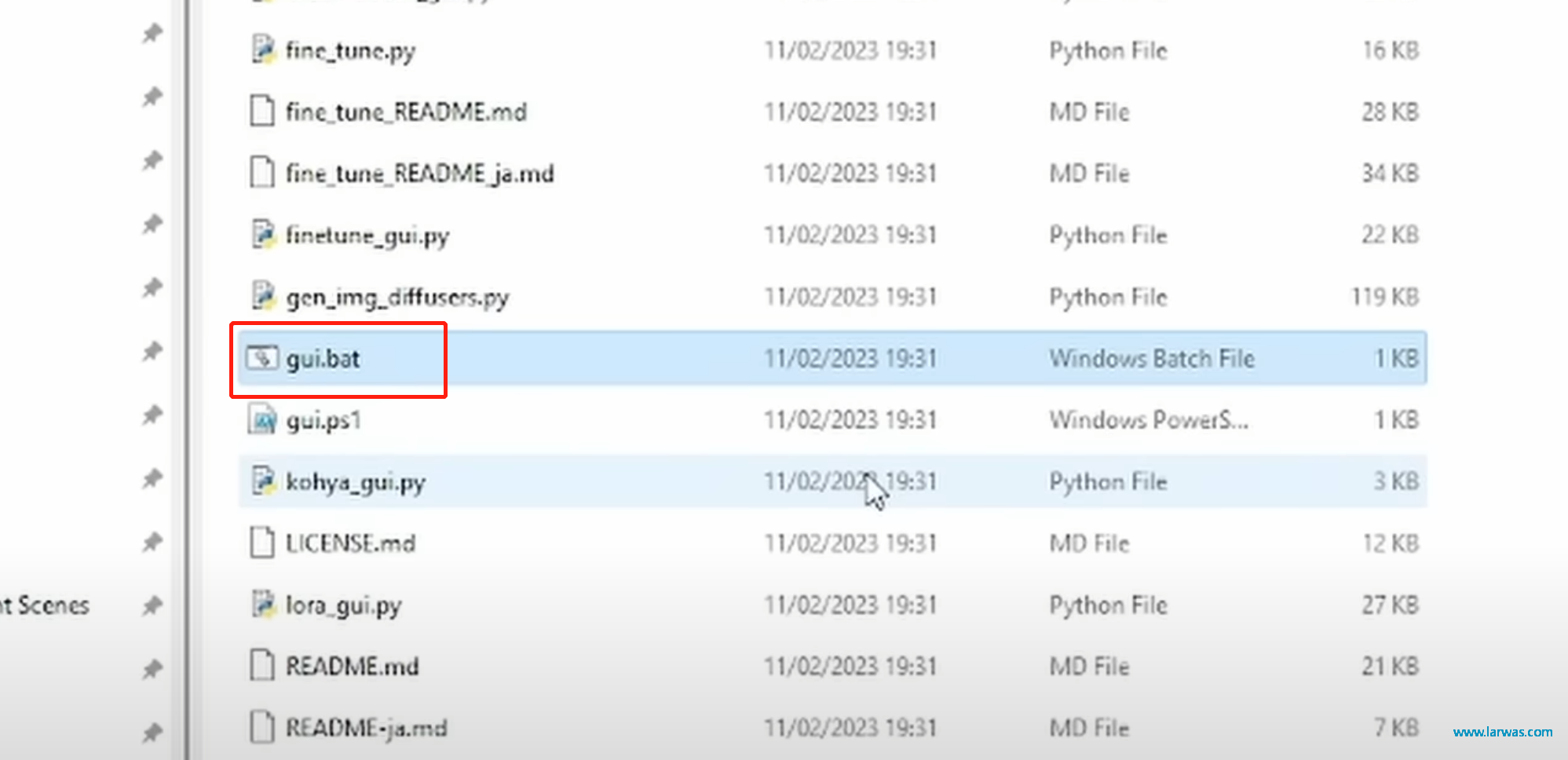 LoRA生成AI模型:运行
使用LoRA教程训练AI模型:使用教程
第一步:选择Dreambooth然后选择一个源模型
这里推荐一下RealisticVision V1.3(一个专注人像的模型,效果很好),下载链接:https://civitai.com/models/4201/realistic-vision-v13(安装到stable-diffusion-webui:models:Stable-diffusion文件夹内即可)
LoRA生成AI模型:运行
使用LoRA教程训练AI模型:使用教程
第一步:选择Dreambooth然后选择一个源模型
这里推荐一下RealisticVision V1.3(一个专注人像的模型,效果很好),下载链接:https://civitai.com/models/4201/realistic-vision-v13(安装到stable-diffusion-webui:models:Stable-diffusion文件夹内即可)
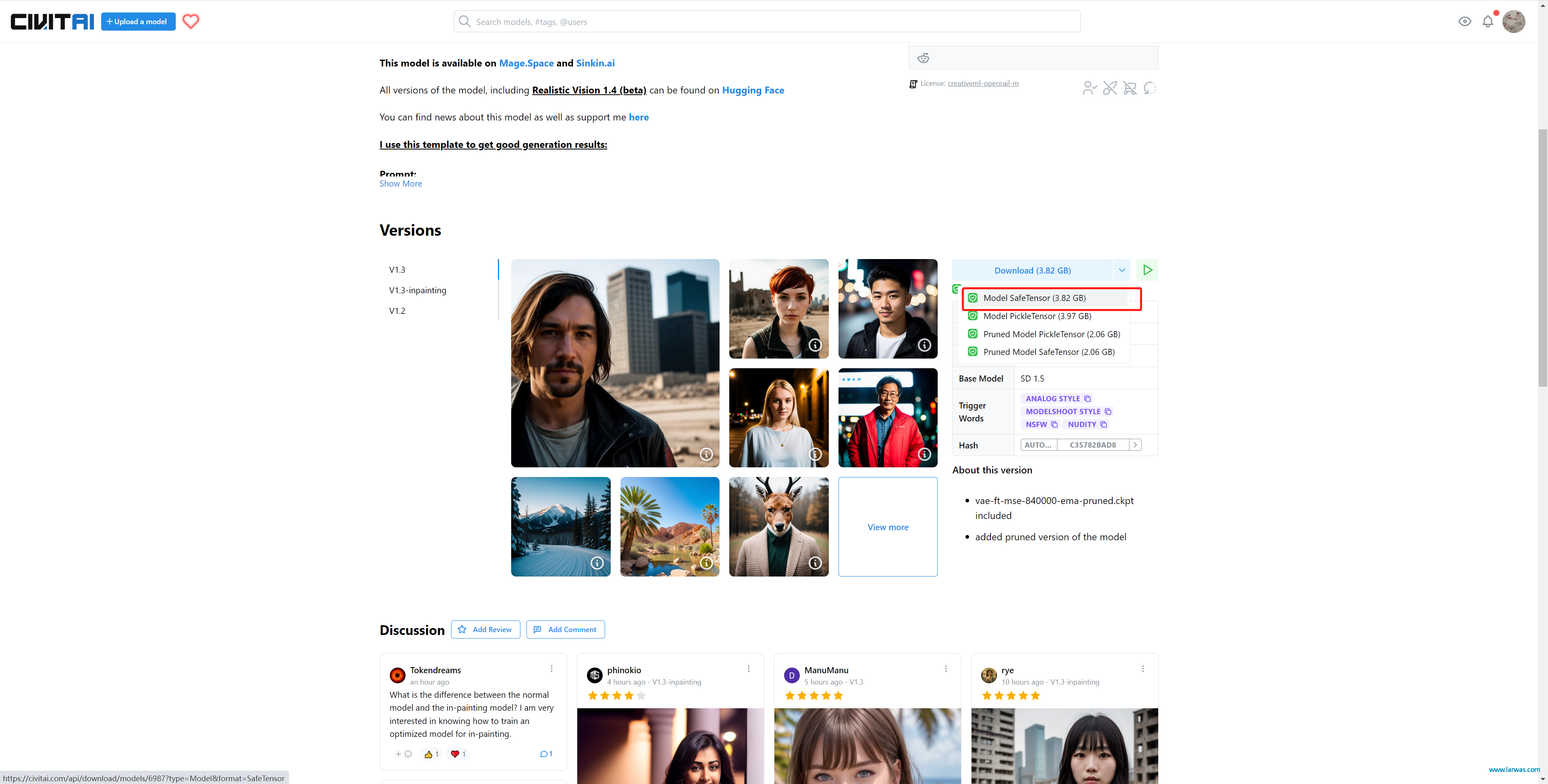 LoRA生成AI模型:Realistic V1.3
没有的话用Stable Diffusion v1.5也可以,比较稳定。
LoRA生成AI模型:Realistic V1.3
没有的话用Stable Diffusion v1.5也可以,比较稳定。
第二步:在document文件夹or桌面,创建一个专门用于模型训练的文件夹“Lora Training Data”,在创建一个新文件夹,起一个你这次训练的用的名字。
 LoRA生成AI模型:文件夹
在这个文件夹之下在创建3个子文件夹image、log和model
LoRA生成AI模型:文件夹
在这个文件夹之下在创建3个子文件夹image、log和model
 LoRA生成AI模型:子文件夹
在image文件夹下面再创建子文件夹100_relisticvision(这里面100代表每张图片训练的次数)
LoRA生成AI模型:子文件夹
在image文件夹下面再创建子文件夹100_relisticvision(这里面100代表每张图片训练的次数)
 LoRA生成AI模型:孙文件夹
第三步:找至少15张你想训练的人像图放到这个文件夹中(同一个人,不同角度,不同远近,不同服装的最好),这样ai才可以全方位的分析你的人脸。
LoRA生成AI模型:孙文件夹
第三步:找至少15张你想训练的人像图放到这个文件夹中(同一个人,不同角度,不同远近,不同服装的最好),这样ai才可以全方位的分析你的人脸。
第四步:回到LoRA,点击Utility,选择Blip Captioning, 然后把你刚才文件夹的路径复制到文本框中。在Prefix里面输入这次训练的主题名称。点击Caption Images,让LoRA帮你解析每张图片。这样你就得到了每张图片对应的解析文档,你可以点击开每个文档检查里面的Prompt是否符合你的图片内容,可以手动进行修改调整。
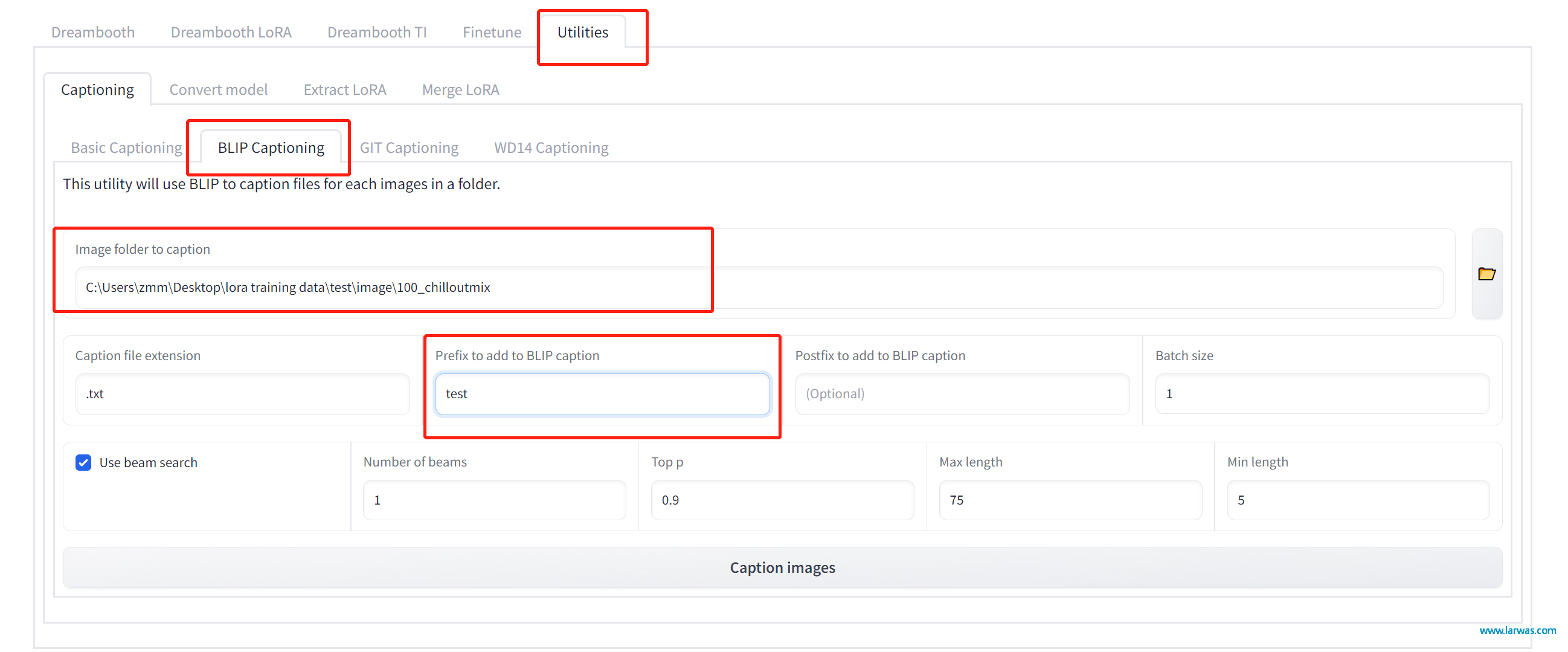 LoRA生成AI模型:Blip
LoRA生成AI模型:Blip
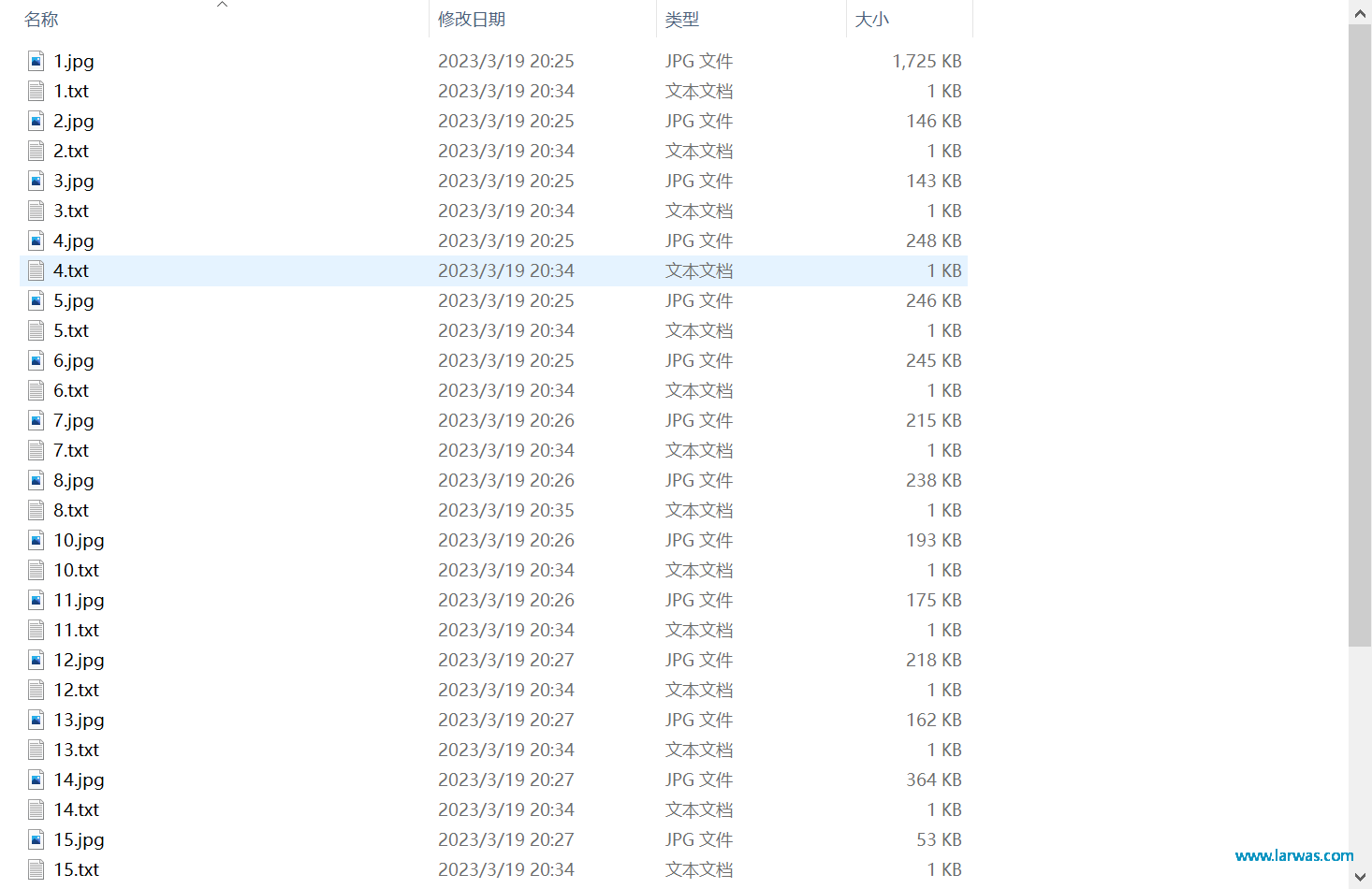 LoRA生成AI模型:解析图片
第五步:回到Dreambooth LoRA,在Folder界面,把前面创建的Image、Output和Log文件夹的地址输入进去(这里注意Image文件夹是母文件夹,不要输入100_test子文件夹的地址)
LoRA生成AI模型:解析图片
第五步:回到Dreambooth LoRA,在Folder界面,把前面创建的Image、Output和Log文件夹的地址输入进去(这里注意Image文件夹是母文件夹,不要输入100_test子文件夹的地址)
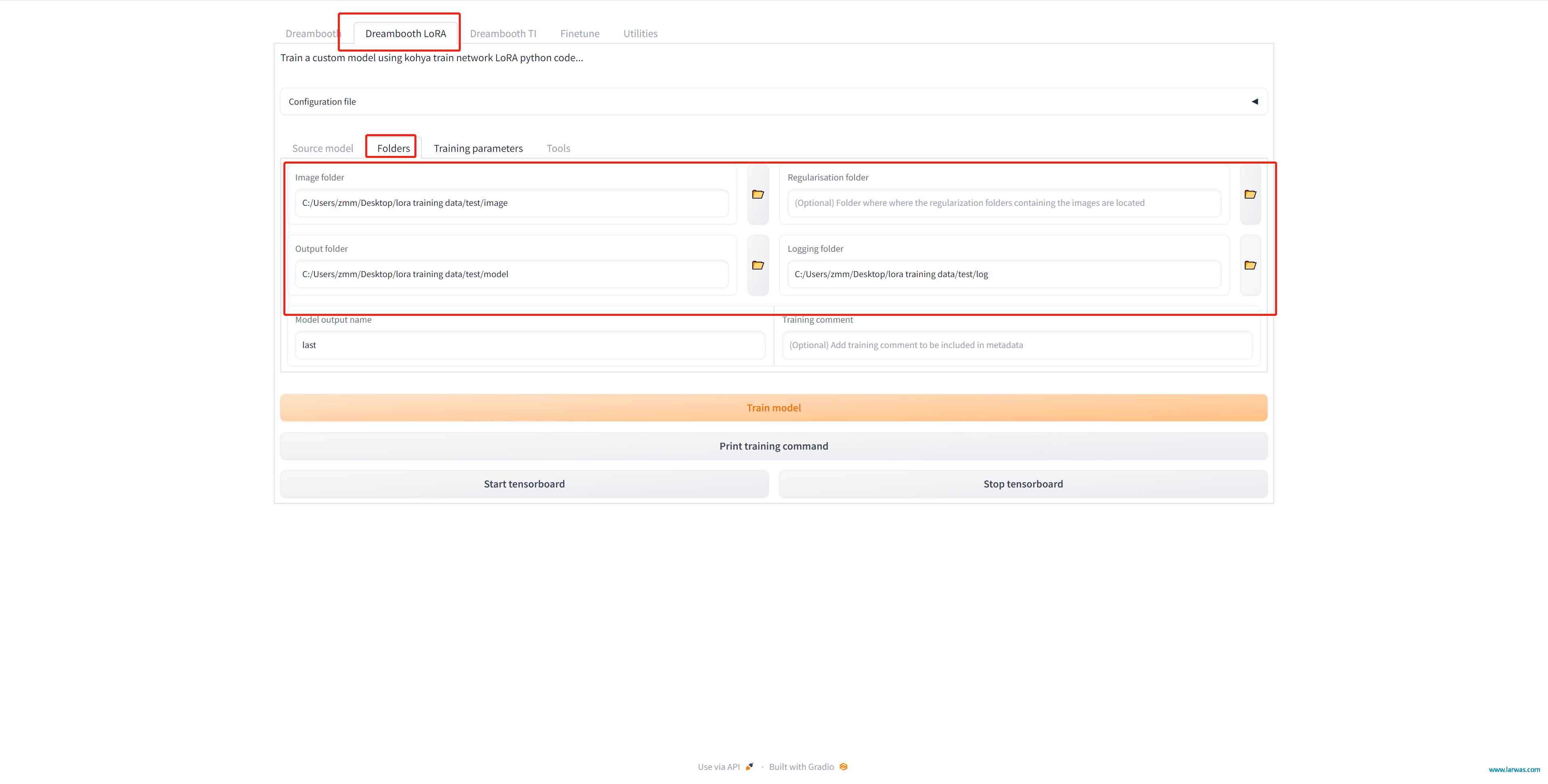 LoRA生成AI模型:输入文件夹地址
LoRA生成AI模型:输入文件夹地址
第六步:Training Parameters这里很复杂,只说几个必要选项,然后点击Train model就可以开始训练了!(按照我的选项,我这个2开头的显卡训练15张图的时间大概是45分钟左右) 1、Train Batch Size:决定了你训练的速度,数值越大速度越快,但越吃显卡,2比1快一倍以此类推。这个要根据你的显卡算力来决定,我是2开头的N卡,选2没什么问题,我见到4开头的卡也就撑死到3,不建议作死试太高数值。
2、Max Resolution:建议调到768,768
3、对于显卡不太好的朋友,建议和我一样把advance parameters下面的Gradient checkpointing和Memory Efficient Attention选上
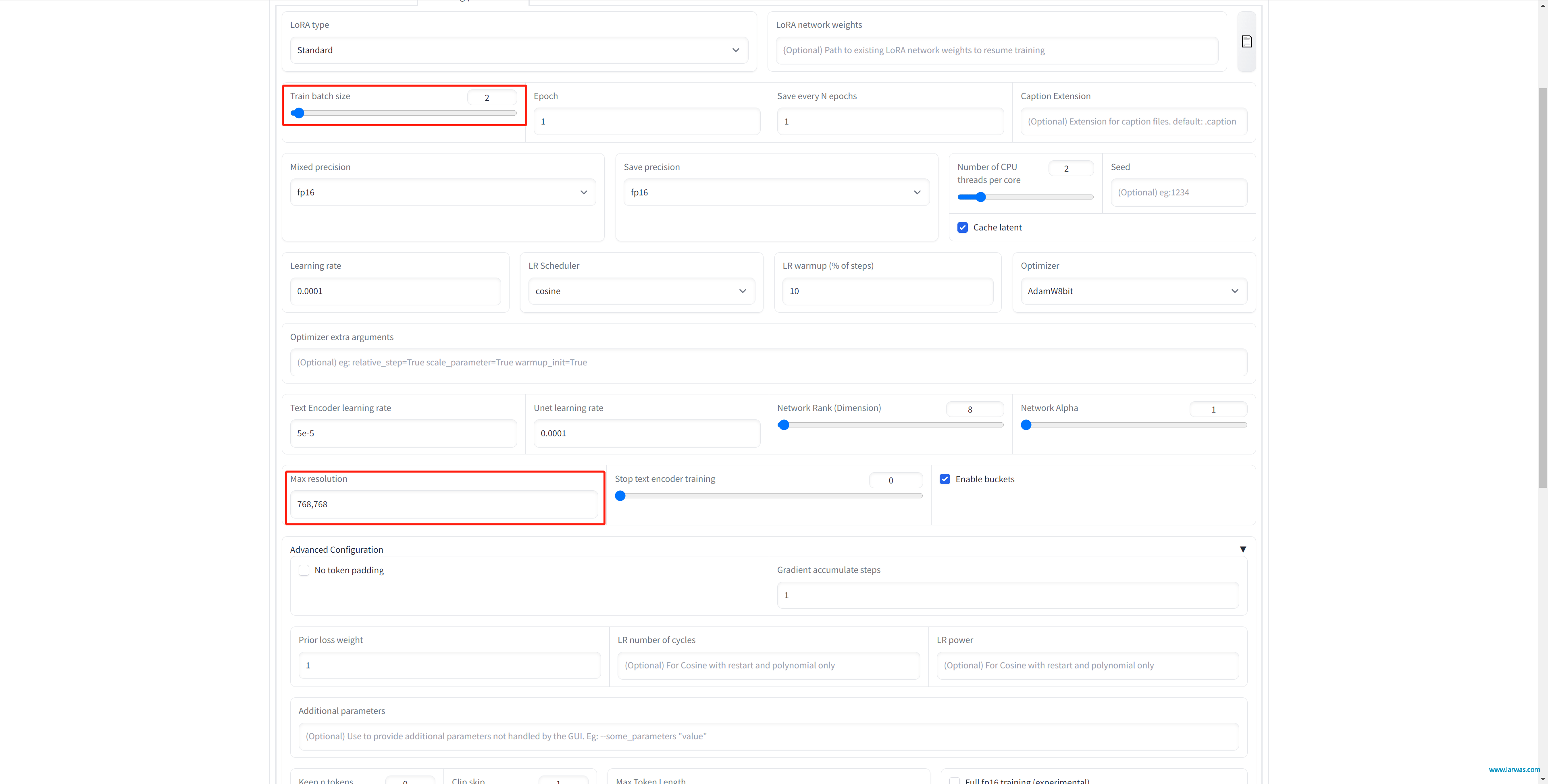 LoRA生成AI模型:训练设置1
LoRA生成AI模型:训练设置1
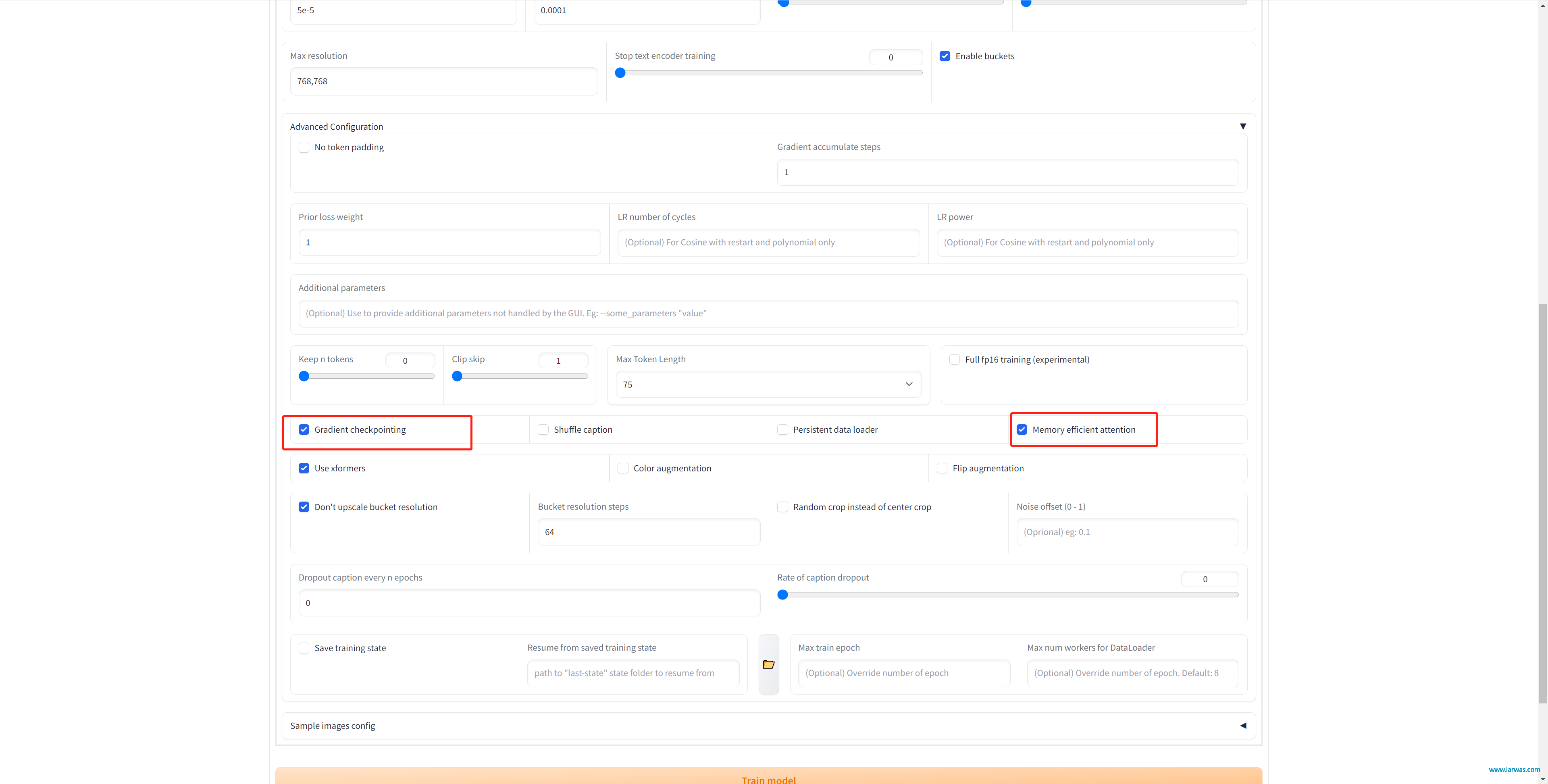 LoRA生成AI模型:训练设置2
LoRA生成AI模型:训练设置2
第七步:训练完成后,你的model文件夹中会出现一个新的文件。将这个文件复制到你的Stable Diffusion文件夹stable-diffusion-webui:models:Lora文件夹下。
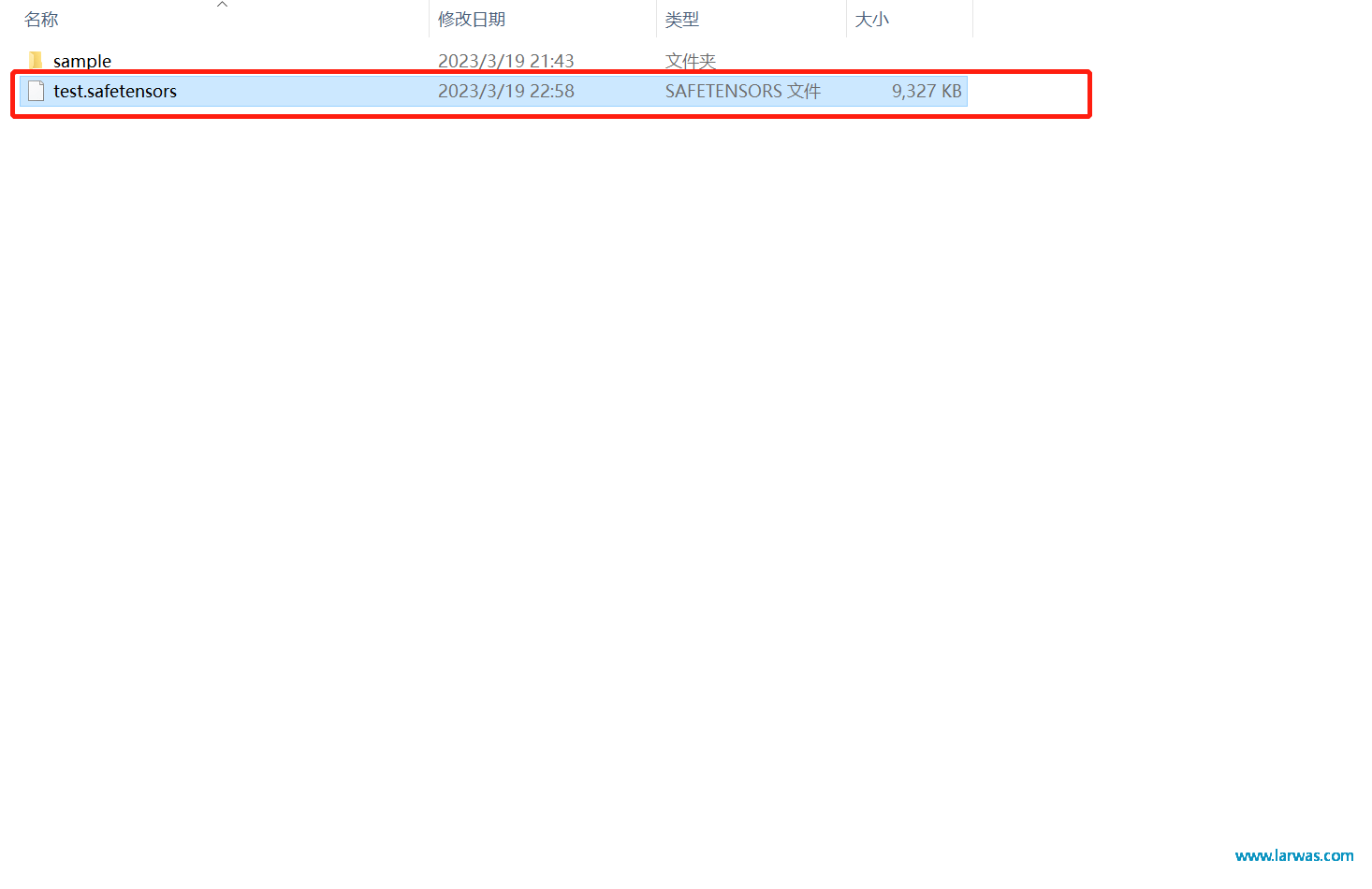 LoRA生成AI模型:训练完毕的文件
LoRA生成AI模型:训练完毕的文件
第八步:打开Stable Diffusion,在Extension Tab:Available下面找到Kohya-ss Additional Networks插件进行安装。 (注意这一步可能SD后台会报错,需要反复尝试,也可以联系我加AIGC互助群来寻求答案)
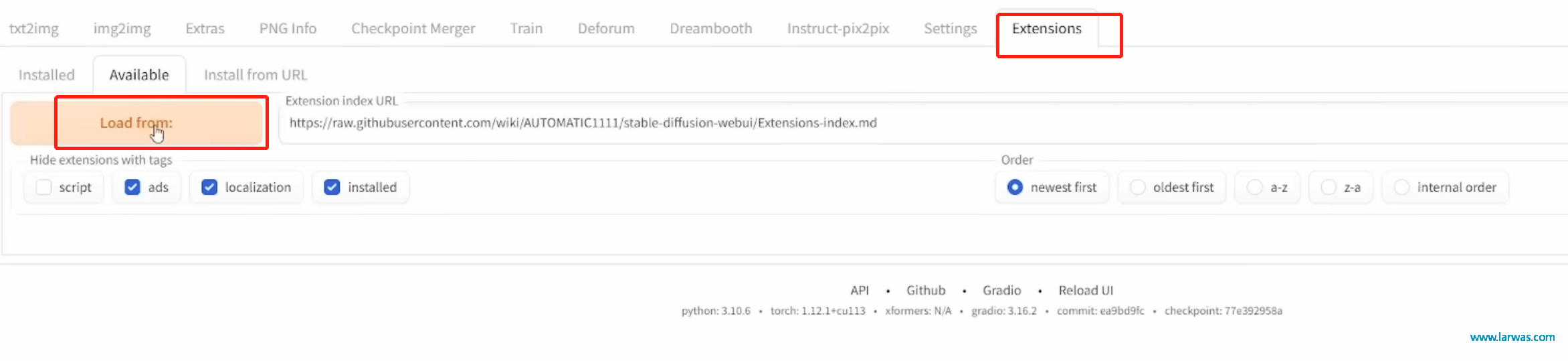 LoRA生成AI模型:下载LoRA插件
LoRA生成AI模型:下载LoRA插件
第九步:安装成功后重启SD就可以使用LoRA了。点击Generate下方的粉红色按钮可以选择Lora模型,然后把LoRA模型的Prompt尽量往前提就好了。 (第一次试验图省事建议使用Realistic Vision,并且在社区内找一张你喜欢的图片的Prompt抄过来用会得到比较好的效果https://civitai.com/models/4201/realistic-vision-v13)
当然你也不要忘了把Stable Diffusion基础的Sampling Method,Steps这些指令调了。
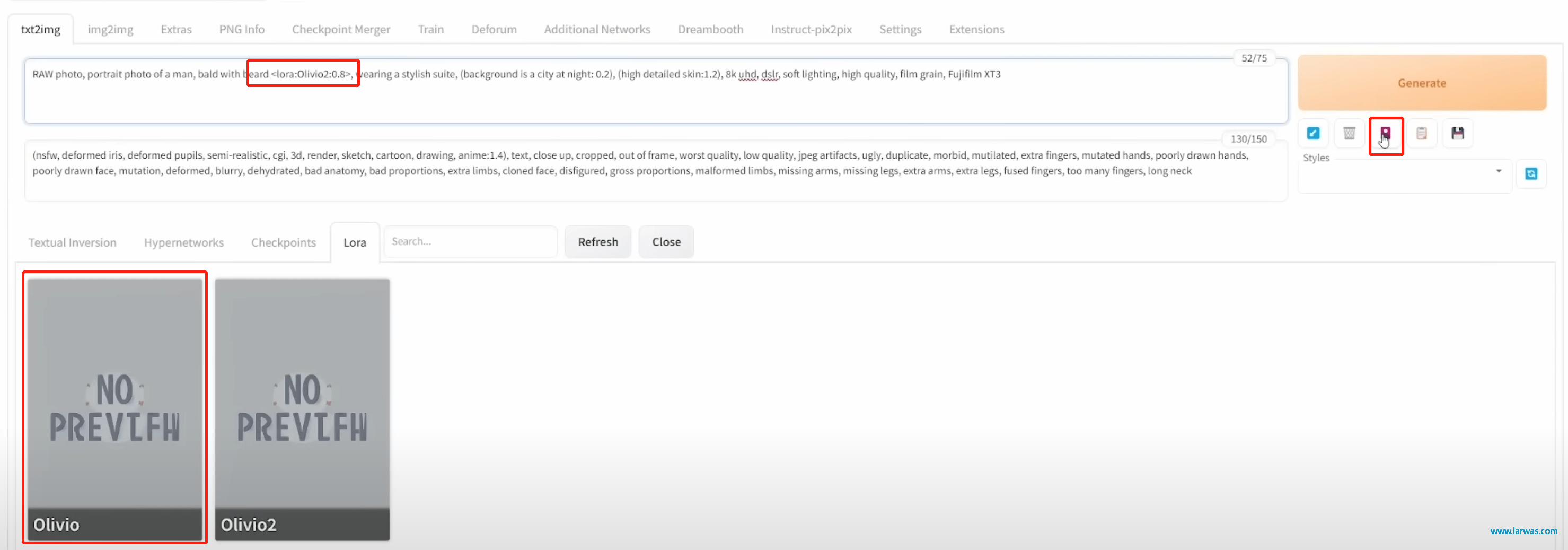 LoRA生成AI模型:Stable Diffusion输入
最后我得到了这张图,你们看出来我是用谁的照片训练得了么?
LoRA生成AI模型:Stable Diffusion输入
最后我得到了这张图,你们看出来我是用谁的照片训练得了么?
 LoRA trained artist
LoRA trained artist
本文为Larwas原创文章,转载无需和我联系,但请注明来自larwas博客 https://larwas.com

- latest comments
- 总共0条评论
最新评论